I S K O
Encyclopedia of Knowledge Organization
Database
by Jakob VoßTable of contents:Abstract:
This article is a preliminary draft of an IEKO article about databases, data formats, and data in general.
1. Introduction
The term database is used with at least five intertwingled connotations:
A data set is an organized collection of data. This is also known as content of a database. For instance, the content of a bibliographic database is a set of bibliographic records. On the other hand a set of records already establishes a database by its own structure. In this sense each database is a also document.
A data model is a formal conceptualization realized in the way a collection of data is organized. Data models are typically described in levels of abstraction from conceptual models to data schemas, formats, and structures. All models at least implicitly assume a connection of their components to ontological entities. For instance, database fields such as “author” and “date” correspond to notions of authorship and time. In this sense each database is also a knowledge organization system.
A database management system is a computer program to facilitate and control the creation and modification of structured sets of data. This includes the definition of data models, the collection of data conforming to these data models and access to the data in secure and performant manner.
A database service or database application is an information system that provides services around a managed set of data, for instance a library catalog, a preprint service, or a web search engine . Database services support more specific use cases than database management system. Their notion of a database goes beyond the realm of data by inclusion of non-technical aspects such as hosting institutions, workflows, and usability.
These aspects of databases are covered in sections on data modeling including basic properties of data and data sets, database management systems, and database services. The history of databases first provides phenomenological background and insights about the nature of databases. A faceted classifion of databases finally helps to locate individual databases and database types from the perspective of Knowledge Organization.
2. History of databases
2.1. Prehistory of databases
Data storing predates written language. The very first instances of databases can be found in form of tally sticks. These counting aids store a single number in a piece of wood or bone. Incremental updates are possible by carving another notch. More elaborated forms of data storage were developed in the Neolithic when domestication of plants and animals led to agricultural economies with increased needs to track amounts of goods.
Clay tokens for counting goods appeared in ancient Near East in the 8th millenium BC. Various kinds and measures of goods such as barley or sheep were represented by marble-sized pieces of clay in different shapes. The number of token types, precursors of modern data types, increased with the complexity of products and societies (Schmandt-Besserat 1996). Around 3500 BC the first cities of Mesopotamia developed a method to store sets of tokens in sealed clay envelopes that eventually led to the invention of writing: a hollow ball of clay called bulla was filled with tokens that represented an obilgation or claim and it was fired to avoid tampering. Sometimes the tokens were also impressed on the surface of the envelope to account the content of a bulla without breaking it. This makes clay bullae the first examples of databases with database index.
At some point people realized that the impressed copies of tokens were enough to store their represented values. Around 3200 BC bullae were replaced by simple pieces of clay with impressions of token shapes and token shapes were replaced by sign of similar shapes and other inscriptions written with a stylus. During third millenium BC writing parted from representation of administrative values to representations of names, words, and eventually phonemes with the advent of cuneiform script.
The full history of writing is more complex for sure. Writing was later invented indepedently at least two times (in China and in Mesoamerica) and multiple factors had an impact on its development. Still it is worth to note that one of the roots of writing systems stems from two characteristics which also define data today: first its primary use for accounting and second the act of copying representations that fully replace original signs.

{kind=link}
2.2. Bookkeeping and archives
…data management before digital data processing…
2.3. Digital databases
…from punched cards to NoSQL and Big Data…
2. Data modeling and semantics
This section will describe basic of data modeling and the nature of structured data.
2.1. Notions of Data
…
2.2. Data modeling
2.2.1. Theory
This section still needs to be simplified and extended by examples!
The set of activities required to design a database or data format is called data modeling. Theoretical foundations of data modeling and have been laid out in the 1970s (ACM 1971; Jr. 1975b). It defines the basic concepts which are still used today (with different meanings because the original sources are unlike read today). As surveyed by Simsion (2007, 34ff.) the data modeling terminology differs, especially between academic and practitioners, but also within communities. Nevertheless there is a rough consensus to differentiate three “realms of interest” which are the real world; ideas about the real world existing in the minds of men; and symbols on some storage medium representing these ideas (Jr. 1975b, II–1). Data modeling then includes several stages from one realm of interest to the next, possibly with sub-steps (Simsion 2007 ch. 3.1) and several levels of description for different stages and applications (Kent 1978 ch. 2.2.2).
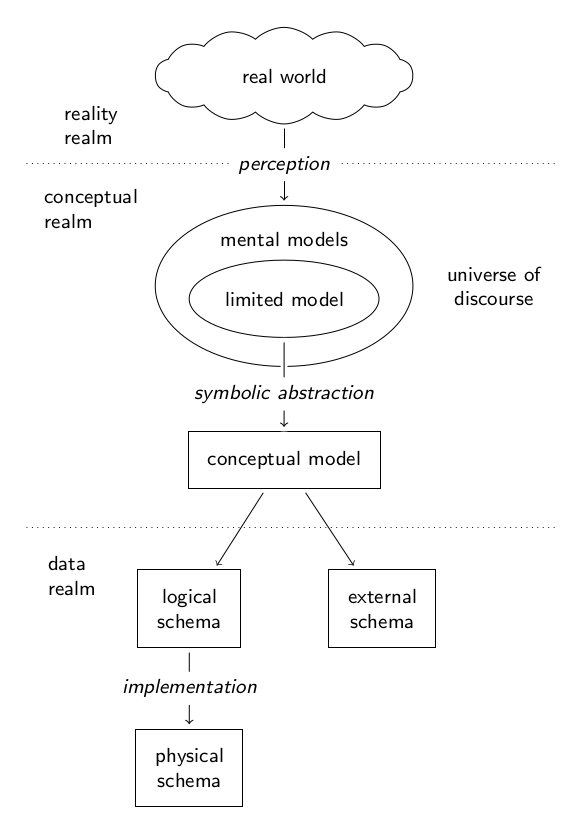
Figure XXX shows a synthesis of data modeling process frameworks from across the data modeling literature. It is mainly based on (Simsion 2007, figs. 3–1) who gives an in-depth review of literature and on (Jr. 1975a, fig. 2).1 A common model of reality that exists in our minds, shared between individuals via any language, is called universe of discourse. We can only express a limited model and try to formally capture it as conceptual schema in a conceptual model. Conceptual models are also called ‘domain models’ or ‘semantic data models’ (Hull and King 1987; Peckham and Maryanski 1988) and come with a graphical notation for better understandability. Most conceptual modeling techniques are based on or influenced by the Entity-Relationship Model (ERM) (Chen, Song, and Zhu 2007). The terms ‘model’ and ‘schema’ are often used synonymously with connotation on expression for schemas or on meaning for models. A conceptual model can be expressed as in a logical schema. It is also called external schema if it only covers parts of a conceptual model (as ‘views’ to the full model) or if it is not primarily meant for storing data. Both logical and external schema must be implemented in a to actually hold data. If data is stored as database, a typically DMBS implements the physical level so users can work on the physical schema. External models can also be realized as data formats and formal ontologies. Examples of languages to express logical and external schemas are SQL, XSD, and RDFS.
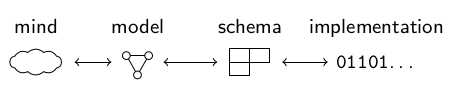
It is important to recognize that each step includes a feedback loop to the prior level of description: constraints of physical schemas influence logical schemas, logical schemas affect conceptual models, and reality is perceived and changed to better fit existing mental models, as language affects the way we think (Whorf 1956). Modelers and architects of information systems often ignore these feedbacks, although it can even cascade through multiple levels. If something cannot be expressed within the artificial boundaries of a system, we often mistakenly assume that is does not exist. In practice data is often created and shaped without a clean, explicit data modeling process. Instead of reflecting mental models, data modeling then starts with a conceptual model or even directly with a logical schema or implementation (Simsion 2007). One can therefore simplify the data modeling process in four levels: mind (reality and mental models), model (conceptual model), schema (logical and external schemas), and implementation (physical schemas) as shown in figure YYYY.
2.2.2. Practice
List and examplain data modeling and schema languages, maybe better in one section
2. Database management systems
Databases are most visible through the software that allows to interact with data: database management system (DBMS) provide controlled access to databases. The purpose of DBMS is to simplify and to secure definition, creation, storage, retrieval, and update of collections of data. This is achieved by limiting interaction with data to a formal database language that hides details of storage, hardware, and algorithms. The most prominent kind of DBMS is relational database management systems (RDBMS) and its Structured Query Language (SQL). Standardization of SQL allows to more or less uniformly manage relation databases in all RDBMS such as Oracle Database, Microsoft SQL Server, MySQL, IBM DB2. Other kinds of databases come with their own database language but the general architecture of DBMS is the same.
2.1. Anatomy of a database management systems
The general architecture of a DBMS conists of the following functional components (figure X).
Data dictionary
The data dictionary contains information about the individual databases stored in the DBMS: it holds metadata about databases. In many cases the data dictionary is also stored as databases together with the data it describes, so it can be accessed in the same way.
Database manager
The database manager is the central control unit of a DBMS. It receives commands and queries from external programs and users and controls execution of commands. The task of the database manager is to ensure consistency (by constraints and integrity checks), reliability (by scheduling), and security (by access control).
Storage engine
The storage engine consists of data structures and processes to read and write data in main memory or secondary storage. This includes database indexes for fast access and caches to support parallel processing (transactions) and data recovery.
Query engine
The query engine translates queries and commands given in the database language into execution plans tha efficiently act on internal data structures of the storage engine.
2.2. Database models
…not finished yet…
Important database models include:
- relational databases (relational model)
- object database (object-oriented model)
- graph database
- document-oriented database
- flat-file databases
- data warehouses (star or snowflake schema)
Outdated models, except for very specialized applications, include network databases (CODASYL) and hierarchical databases (except for file system).
NoSQL broadly refers to all non-relation models. Special kinds of NoSQL databases for a specialized data types include key-value stores, XML databases, geospatial databases, and triple stores. The latter often include inference rules (deductive database). Another special feature found in some DBMS is versioning (temporal databases).
Other specialized models such as column-oriented databases mostly differ by implementation to increase performance for their applications.
Hierarchical file systems and tabular spreadsheets are often used as databases despite or because of their simplicity.
2.3. Application
…
Database management system abstracts from operating systems and hardware so applications can focus on data models and content. The abstraction hides physical schema (see data modeling…)
At least in theory choice and maintenance of DBMS can therefore best be hand off to IT departments.
Relevant for applications: Knowledge of the particular database model and possibility to define and modify databases (access to the data dictionary).
In practice data is also shaped by other aspects of DBMS than its database models: usability, scripting, APIs, popularity… (example: FileMaker).
In practice levels of abstraction are not clearly separated and depend on each other.
2. Database services and information systems
…Databases are core parts of more general information systems….
3. Classification of databases
Individual databases and database types can be grouped and described according to multiple criteria. From the perspective of Knowledge Organization databases can be classified with a faceted classification of four semantic categories: domain of application, content type, database model, and implementation. The categories can roughly be mapped to the RDA/ONIX categories content for domain of application and content type and to carrier for database model and implementation (Kiorgaard 2006). This comparison should be taken with care as both dimensions are connected (Green and Fallgren 2007). In particular what is stored in a database (domain of application) influences how it is structured (content type and database model) and vice versa.
Domain of Application
The most practical aspect of a database is its intended or its actual use. Subcategories of this domain include:
The subject area indicates what principal kind of information is managed with the database (e.g. chemical databases, biological databases, financial databases, bibliographical databases, music database…).
The audience or operator indicates who typically uses the database in which ways (e.g. public databases, private databases, government databases, decision support systems, collaborative databases…).
The type of access identifies methods and requirements to use the database (e.g. online databases, free databases, commercial databases…).
For instance most library catalogs mainly manage bibliographic metadata. Their audience includes the general public having read access and selected librarians having write access.
Content Type
This aspect refers to the type of records or documents stored in a database. Content types are defined by a common data model or data format that all individual records must conform to (see data modeling). Typical database types by content type include:
Document repositories store documents such as texts (full-text databases), media files (multimedia databases), or other digital objects.
Knowledge bases store factual statements. This includes most numeric databases (big data) and bibliographic databases (metadata).
Spatial database store geographical information.
Terminology databases store units of language and concepts.
Content types mainly dictate how data from databases can be used and combined in other information systems, independently from technical and organizational aspects (see interoperability).
Database Model
The database model of a database is a fundamental paradigm that influences how data can best be organized in a database. That is why this aspect of databases is mostly referred to as database type. Popular database models include relational databases, object database, graph database, document-oriented database, flat-file database, and data warehouses.
Basic properties of distinct database models are described in section database management systems.
Implementation
Technical aspects of databases are more relevant in computer science than in Knowledge Organization. Nevertheless types of implementation influence how databases can be used, so implementations play an important role for instance for usability.
Examples of categories in this facet of database classification include distributed databases, in-memory databases, and blockchains.
4. Summary
…
References
ACM, ed. 1971. “CODASYL Database Task Group Report.” Association for Computing Machinery.
Chen, Chaomei, Il-Yeol Song, and Weizhong Zhu. 2007. “Trends in Conceptual Modeling: Citation Analysis of the Er Conference Papers (1975-2005).” In Proceedings of the 11th Issi, 189–200. CSIC. http://www.conceptualmodeling.org/ER-Citation-Analysis-ISSI2007.pdf.
Green, Rebecca, and Nancy Fallgren. 2007. “Anticipating New Media: A Faceted Classification of Material Types.” In Proceedings of the North American Symposium on Knowledge Organization, edited by Joseph T. Tennis, 1:87–99. https://doi.org/10.7152/nasko.v1i1.12837.
Q57754496 Hull, Richard, and Roger King. 1987. “Semantic Database Modeling: Survey, Applications, and Research Issues.” ACM Computing Surveys 19 (3): 201–60. https://doi.org/10.1145/45072.45073.
Jr., Thomas B. Steel. 1975a. “Data Base Standardization - a Status Report.” In IBM Symposium: Data Base Systems, edited by Helmut F. Hasselmeier and Wilhelm G. Spruth, 39:362–86. LNCS. Springer.
Q57628849 ———, ed. 1975b. “Interim Report Ansi/X3/Sparc Study Group on Data Base Management Systems 75-02-08.” FDT Bulletin of ACM SIGMOD 7 (2): 1–140.
Q25625532 Kent, William. 1978. Data and Reality. North Holland Publishing Company.
Kiorgaard, Deirdre, ed. 2006. “RDA/Onix Framework for Resource Categorization.” Version 1. https://www.loc.gov/marc/marbi/2007/5chair10.pdf.
Q57754498 Peckham, Joan, and Fred Maryanski. 1988. “Semantic Data Models.” ACM Computing Surveys 20 (3): 153–89. https://doi.org/10.1145/62061.62062.
Q57532821 Schmandt-Besserat, Denise. 1996. How Writing Came About. University of Texas Press.
Q25809164 Simsion, Graeme. 2007. Data Modeling Theory and Practice. Technics Publications.
Q57628579 Whorf, Benjamin Lee. 1956. Language, Thought, and Reality. Edited by John Bissell Carroll. MIT Press.